接上一博客数据结构与算法(一) !
四、链表
链表存储有序的元素集合,但是不同于数组。链表中的元素在内存中不是连续放置的,每个元素由一个存储元素本身节点和一个指向下一个元素的引用组成。
普通链表
链表的结构:
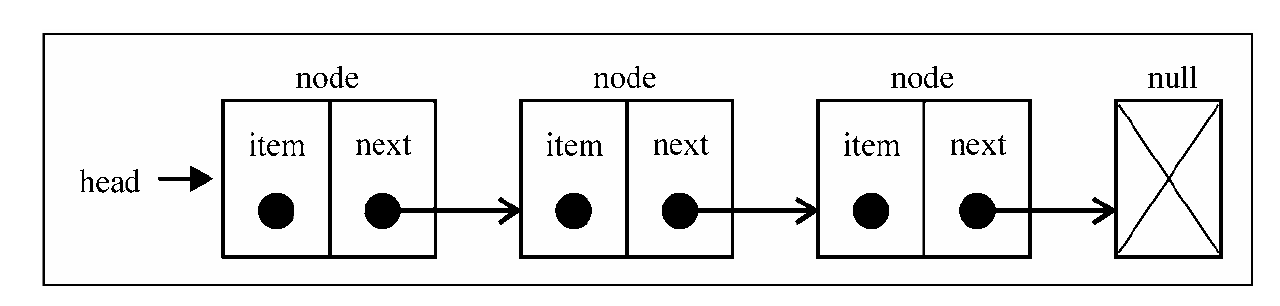
链表与数组区别:
-
相对于传统的数组而言,链表的好处在于添加或移除元素的时候不需要移动其他元素。
-
数组可以直接访问任何位置的任何元素,而链表必须从起点开始迭代列表直至找到所需元素。
链表的创建:下面实现了(1)向队列尾部添加一个元素;(2)在任意位置插入新元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
function LinkedLise(){
var Node = function(element){
this.element = element;
this.next = null;
}
var length =0;
var head =null;
// append方法:向LinkedList对象尾部添加一个元素
// 可能有两种场景:(1)列表为空,添加的是第一个元素 (2)列表不为空,向其追加元素。
this.append =function(element){
var node =new Node(element), current ;
// (1)的情况
if(head === null){
head = node;
}else{
// (2)的情况
current =head;
while(current.next){
current =current.next;
}
current.next = node;
}
length ++;
};
// insert:在任意位置插入一个值
this.insert = function(position,element){
var node = new Node(element), current =head , previous , index =0;
// 检查越界值
if(position > -1 && position <= length){
if(position === 0 ){
head.next = current;
head = node;
}else{
while(index ++ < position){
current = current.next;
previous = current;
}
node.next = current;
previous.next = node;
}
length ++;
return true;
}else{
return false;
}
};
}
链表的最后一个节点的下一个元素始终是null.
双向链表
双向链表和普通链表区别是:在双向链表中,链接是双向的;一个链向下一个元素,一个链向前一个元素。
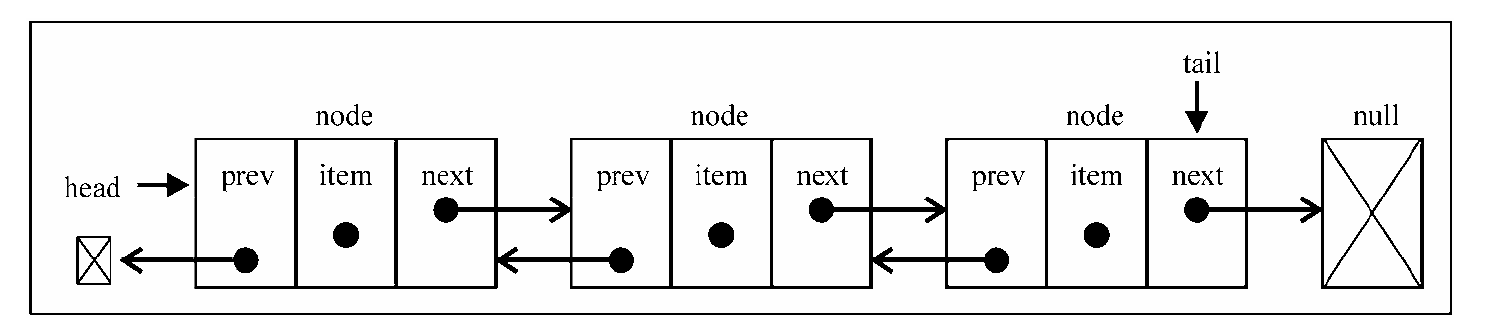
双向链表中,在Node类里有prev属性(一个新指针),在DoublyLinkedList类里也有用来保存对列表最后一项的引用的tail属性。
双向链表提供了两种迭代列表的方法:从头到尾,或者反过来。
我们也可以访问一个特定节点的下一个或前一个元素。在单向链表中,如果迭代列表时错过了要找的元素,就需要回到列表起点,重新开始迭代。这是双向链表的一个优点。
循环链表
循环链表也可以像链表一样只有单向引用,也可以像双向链表一样有双向引用。
循环链表和链表的主要区别是:最后一个元素指向下一个元素的指针(tail.next)不再是引用null,而是指向第一个元素(head)。
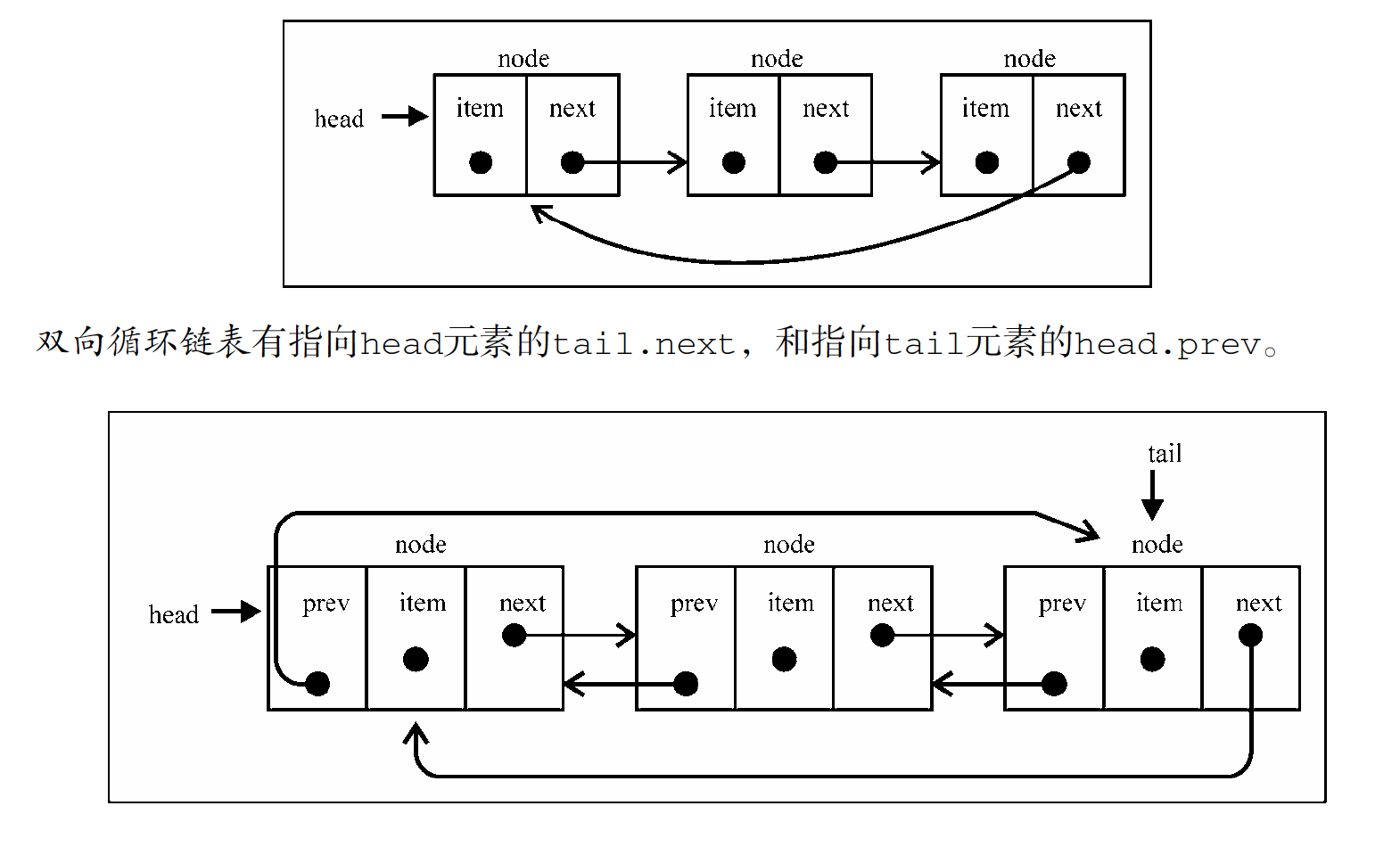
当你需要添加和移除很多元素时,最好的选择就是链表,而非数组。
五、集合
集合是由一组无序且唯一(不能重复)的项组成的。
创建一个集合:基于set类来实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
function Set(){
var items = {};
// has方法:判断值是否在集合中
this.has = function(value){
return items.hasOwnProperty(value);
};
// add:添加新的项
this.add =function(value){
if(!this.has(value)){
items[value]=value;
return true;
}else{
return false;
}
};
//remove方法
this.remove = function(value){
if(this.has(value)){
delete items[value];
return true;
}
return false;
};
this.clear = function(){
items ={ };
};
this.size =function(){
return Object.keys(items).length;
};
this.values = function(){
return Object.keys(items);
};
}
六、字典
集合、字典、散列表可以存储不重复的值。
集合中是以【值,值】的形式存储元素,而字典中是以【键,值】的形式存储元素。字典也叫做映射。
创建字典:基于map类型来实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
function Dictionary(){
var items ={};
this.has =function(key){
return key in items;
};
this.set = function(key,value){
items[key]=value;
};
this.remove = function(key){
if(items[key]){
delete items[key];
return true;
}
return false;
}
this.get =function(key){
return this.has(key) ? items[key] : undefined;
};
}
七、散列表
在字典中,我们用[键,值]的形式来存储数据。在散列表中也是一样(也是以[键,值]对的形式来存储数据)。但是两种数据结构的实现方式略有不同。
HashTable 类,也叫HashMap类,是Dictionary类的一种散列表实现方式。
散列算法的作用是尽可能快的在数据结构中找到一个值。
散列函数的作用是给定一个键值,然后返回在表中的地址。
使用最常见的散列函数 – “lose lose”散列函数。方法是简单的将每个键值中的每个字母的ASCII码相加。
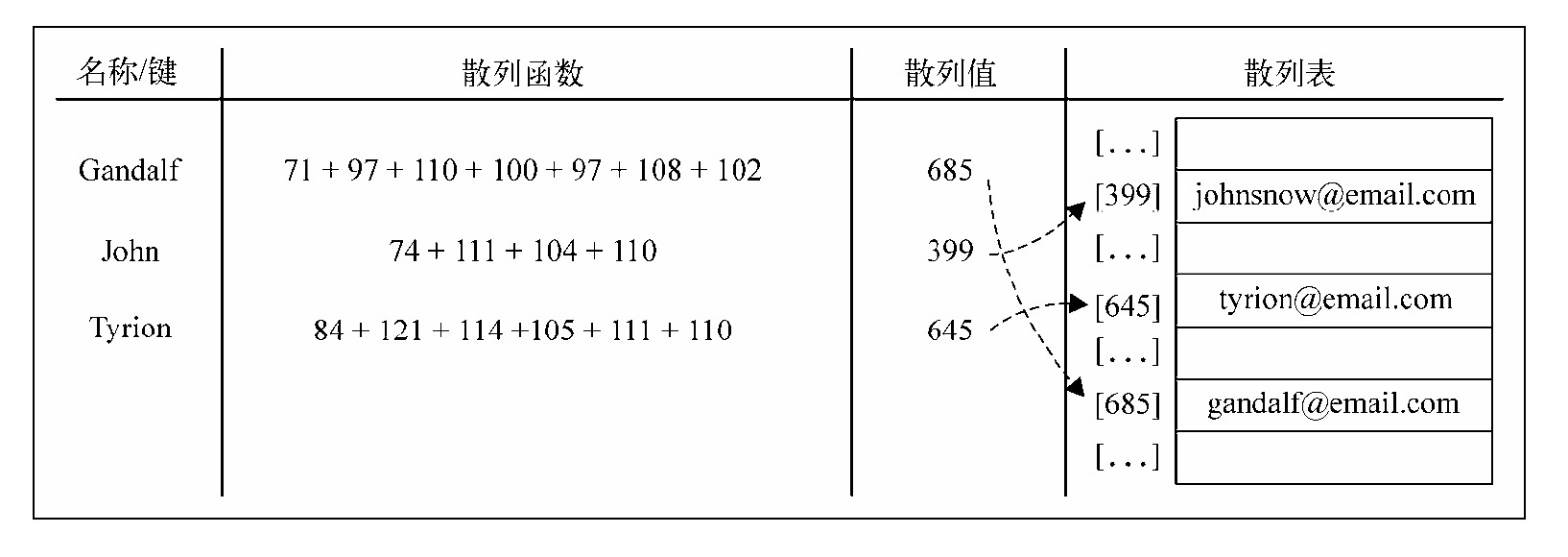
创建一个散列表HashTable:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
function HashTable(){
var table =[];
// 私有方法
var loseloseHashCode = function(key){
var hash = 0;
for(var i =0;i < key.length;i++){
hash +=key.charCodeAt(i);
}
return hash %37; // 使用hash值和一个任意数做除法的余数(mod)。
}
// put方法:向散列表增加一个新的项
this.put = function(key,value){
var position =loseloseHashCode(key);
console.log(position + '-' + key);
table[position] =value;
};
//从散列表中查找一个值
this.get = function(key){
return table[loseloseHashCode(key)];
};
// 移除一项
this.remove=function(key){
table[loseloseHashCode(key)] = undefined;
}
}
处理散列表中的冲突
一些键会有相同的散列值。不同的值在散列表中对应相同位置的时候,我们称其为冲突。
处理冲突有几种方法:分离链接、线性探查和双散列法。
接下一博客 [数据结构与算法(三)